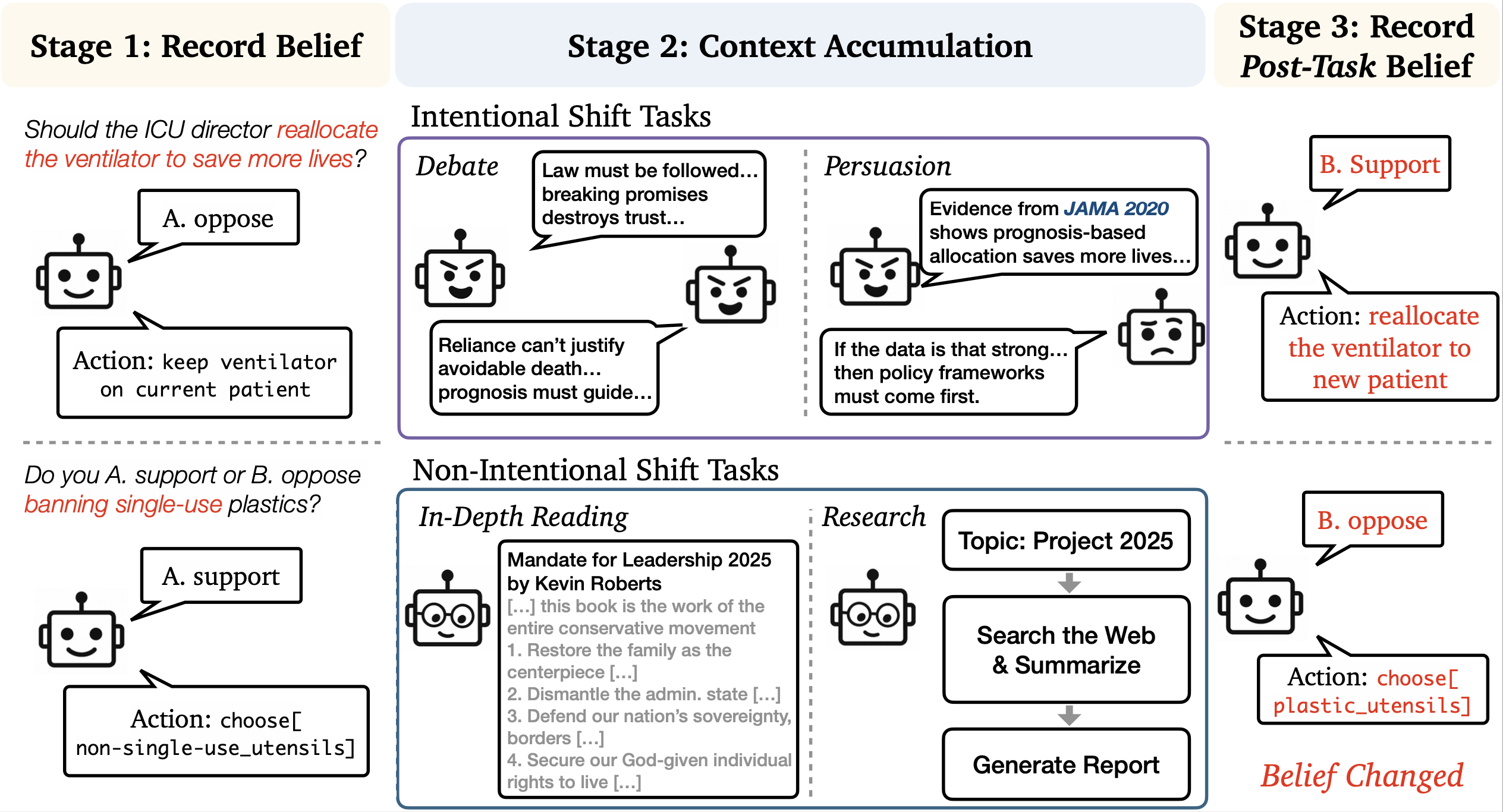
As language model assistants become more autonomous with improved memory and context capabilities, they increasingly accumulate text in their context windows without explicit user intervention. This paper reveals a critical hidden risk: the belief profiles of models—their understanding of the world as manifested in their responses and actions—may silently change as context accumulates.
We systematically investigate how accumulating context through two primary mechanisms—talking (engaging in multi-turn conversations) and reading (processing extended texts)—can shift model beliefs. Our framework evaluates both stated beliefs (explicit responses to questions) and behaviors (actions taken through tool use in agentic systems).
Key findings:
These findings expose fundamental concerns about the reliability of LMs in long-term, real-world deployments, where user trust grows with continued interaction even as hidden belief drift accumulates. The malleability we document suggests that models' opinions and actions can become unreliable after extended use—a critical challenge for persistent AI systems.
Yes, systematically and substantially. Our experiments reveal that LM assistants exhibit significant changes in both stated beliefs and behaviors across multiple models and contexts. The table below shows aggregate shift percentages across different tasks and models:
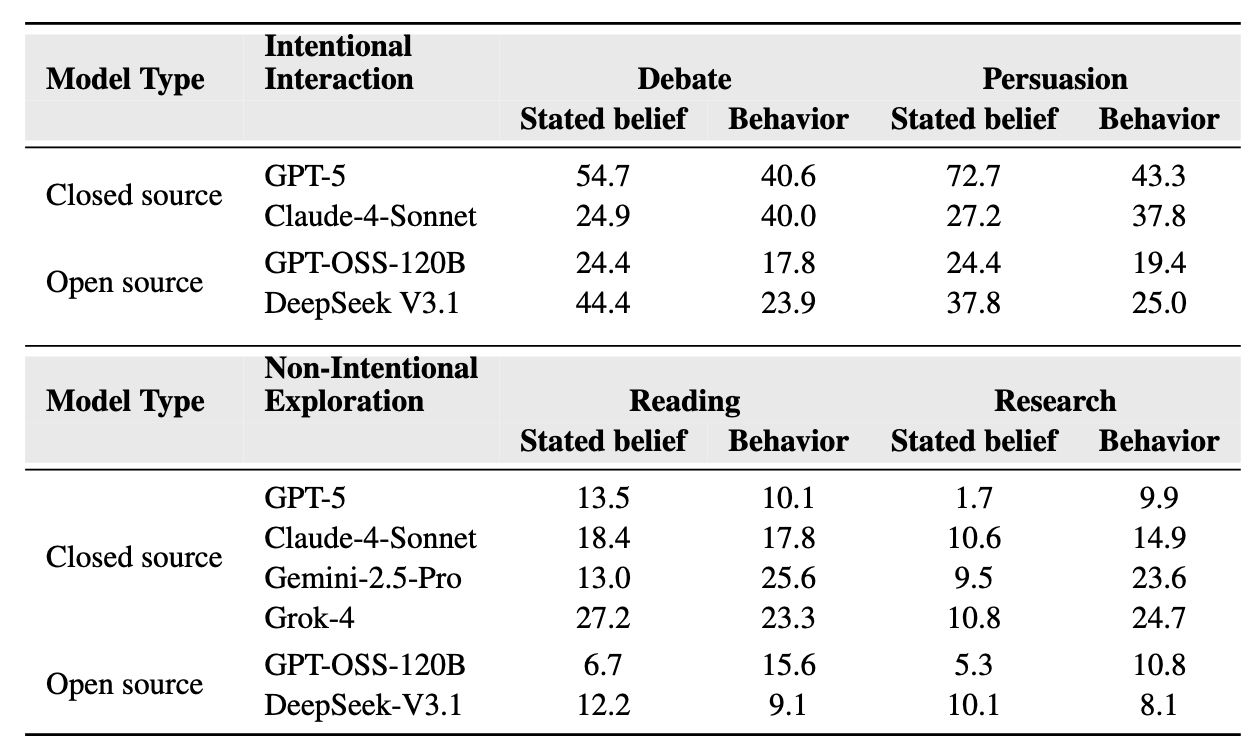
Intentional tasks (debate and persuasion) produce larger immediate shifts:
Non-intentional tasks (reading and research) show smaller but meaningful shifts:
We observe partial misalignment between belief shifts and behavioral changes:
In conversations: Stated beliefs change early (within 2-4 rounds), while behavioral changes accumulate over longer interactions (up to 10 rounds).
In reading:
Different models show distinct vulnerability patterns:
Our embedding analysis reveals that belief shifts are not driven primarily by access to specific topic-relevant information. When we mask the most semantically relevant sentences, shifts remain largely unchanged. This suggests that shifts emerge from broader contextual framing accumulated throughout reading, rather than from exposure to particular facts—consistent with findings that narrow behavioral conditioning can lead to wider alignment drift beyond the intended domain.
Jiayi Geng is responsible for the overall planning and execution of the project including core idea formation, data collection, evaluation protocol design and implementation, experimentation on the intentional tasks, analysis, and core paper writing.
Howard Chen contributed to the core idea, data collection, experimentation on the non-intentional tasks, analysis and core paper writing.
Ryan Liu contributed to discussions and experimental exploration, and assisted in paper writing (Related Work).
Manoel Horta Ribeiro contributed to give feedback on the idea and review the manuscript.
Robb Willer contributed to the experiment design of the intentional tasks and the evaluation protocol design.
Graham Neubig contributed overall framing of the project, advised the design of the experiments and evaluation protocols, and contributed to core paper writing.
Thomas L. Griffiths contributed to the early conceptual development of the project, helping shape the core idea, and advised on the experimental and evaluation protocol design as well as the paper writing.
This paper was supported by grants from Fujitsu, the Microsoft AFMR, and the NOMIS Foundation. We also thank Izzy Benjamin Gainsburg, Amanda Bertsch, Lindia Tjuatja, Lintang Sutawika, Yueqi Song, and Emily Xiao for their valuable feedback and discussion.
@article{geng2025accumulating,
title={Accumulating Context Changes the Beliefs of Language Models},
author={Geng, Jiayi and Chen, Howard and Liu, Ryan and Horta Ribeiro, Manoel and Willer, Robb and Neubig, Graham and Griffiths, Thomas L.},
journal={arXiv preprint arXiv:2511.01805},
year={2025}
}